Is it all over for filmmakers?
Another month and another model update accompanied by a massive amount of marketing, Linkedin spam, spin, and dubious claims.
Two years ago I debunked claims that Sora would destroy filmmaking. It’s still mostly garbage today. Last year I punished myself by testing Google's Veo model every day for a month. I am still recovering from the AI slop induced nausea.
Last week’s new model was a version 2.0 update of Bytedance’s Seedance video generator. As always, one has the feeling that lies are travelling around the world twice before the truth has time to put its shoes on. So here I am for another debunk.
One of the most talked about demos of the Seedance 2.0 model was a fight scene depicting Tom Cruise and Brad Pitt (two fight scenes if we count the costume changes). The claims by the news outlets and on social media were that an Irish filmmaker typed just two lines into Seedance 2.0 and 30 seconds later a full formed fight scene with multiple angles was generated.

“Extraordinary claims require extraordinary evidence” - Carl Sagan
The usual villainy on LinkedIn drowned the site with the video along with the claims that “Hollywood was over”. As shown in the past these are often code words for ‘Jews must go’ because they never talk about any other country’s film industry like that.
Imagine if the anti-Semites on LinkedIn decided one morning to be racist to the Chinese. Their posts would read like this:
'Google just released Veo 4.5 and it is a game changer! Hengdian World Studios is shaking in their boots! The Chinese film industry is about to be cooked!’
You'd condemn that language because it is less coded and more obviously racist. You'd openly say that is an attack on millions of hard working Chinese people working in the Chinese media industry.
Because of that LinkedIn has become a highly toxic environment full of unqualified AI meddlers who are paid to post hyperbole. What usually happens is that an AI company releases a new model. They give sample videos to marketing companies who then send the samples to influencers with a script for social media that usually reads ‘Hollywood is over. I generated this full scene with with just two prompts. What used to cost $20,000,000 now costs pennies. This is a game changer that democratises filmmaking!’
LinkedIn is really something.
Then there’s the list of claims that self-anointed experts and salesmen make which inevitably lead to disappointment.
If any of these people knew anything about filmmaking then they’d know that filmmaking was democratised many years ago starting with the earliest portable cameras down to the modern day smartphone which now has a sensor that can capture better quality images than the cameras used to film ‘The Blair Watch Project’. Yet despite everyone owning a high resolution video camera now, how many great filmmakers are there? For every 25 million people who own a smartphone there is only one who can shoot a film like Left-Handed Girl (shot entirely on an iPhone). Filmmaking is not just about democratising technology. One has to learn every aspect of the craft, push themselves to create original stories and then have the taste to execute the story to high standards.
So when you ask those AI influencers to prove they generated the demos they either refuse to reply or they respond with ‘Sorry I no longer have access because I lost the password’ and other similar excuses. So whenever you see a popular AI video demo by an influencer ask them:
1. For the prompts so you can test them yourself.
2. For a live demonstration.
3. Behind the scenes workflow.
If they shy away from transparency it is because they were given the demo by the AI company and that a lot more work was needed to make the demo than just 'prompting'.
So I had to call bogus on this immediately. After a lifetime of shooting in college, in film school, being on sets and running post-production; and after years of deep dives into every new piece of technology and testing all the cloud and local AI models, the claims being made immediately rubbed me up the wrong way. Other demos of the Seedance model had the usual errors we have come to expect from AI video generators.

Badly rendered Chinese writing that means nothing. Errors and low quality outlines everywhere.
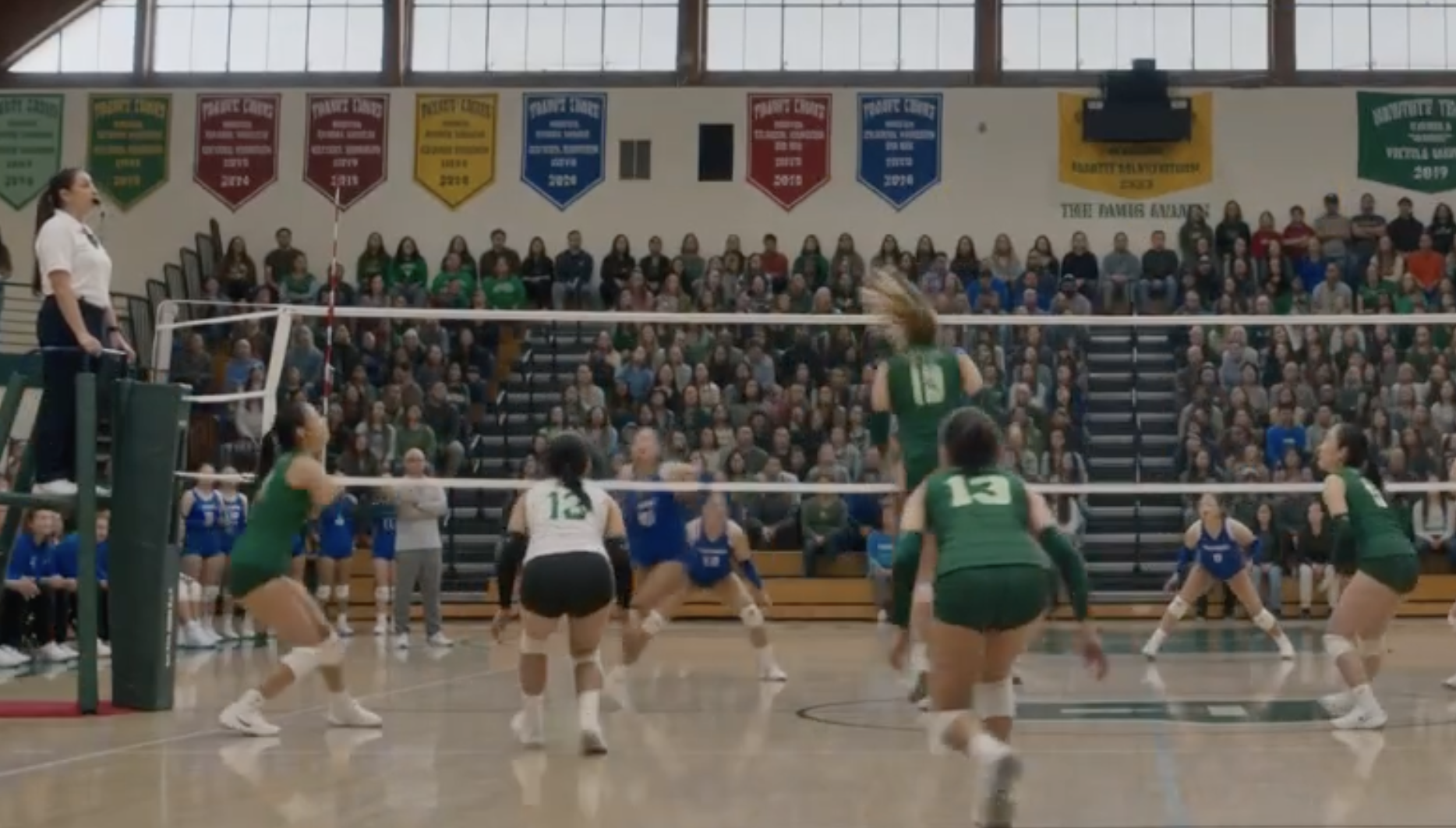
There are three number 13s playing for one team and one of them is wearing inverted colours. The net doesn’t have a net.

It’s supposed to be Japanese writing but it’s gibberish. There’s a boy in a white t-shirt whose feet point the wrong way.

In the generated video of a pianist, the position of his hands don’t match the higher pitched keys being played.
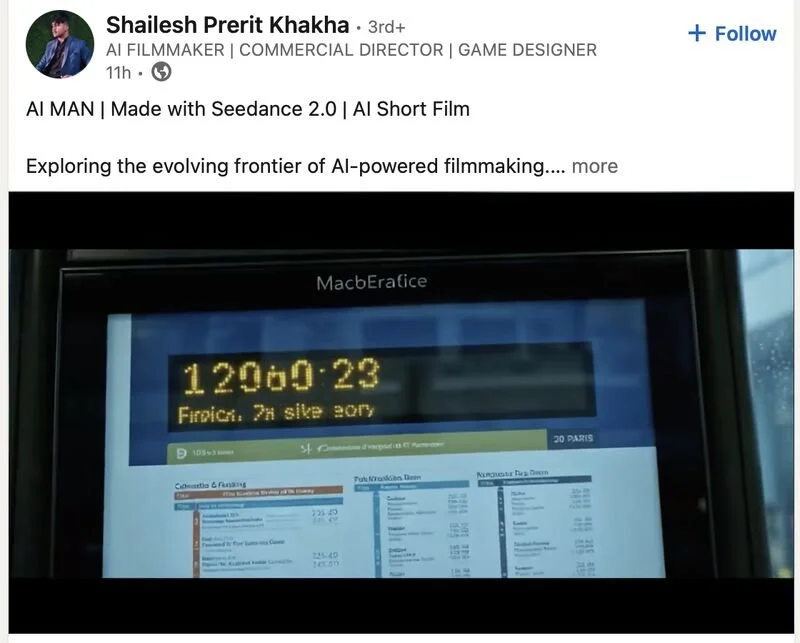
Very readable text

When there’s a group of people close together the same expression is rendered on all of them, gibberish writing and signage is common, inconsistencies in the architecture, errors such as the incomplete Walkman strap.

A demo labelled ‘Impressive Realism’ had lawns that extend to the road, no kerbs and cars parked on the lawns.

A man returns home. His apartment number is 219 and it is next to apartment 023. Every door in the hallway has a random design.

He inserts a key into his door that already has (deformed) keys in it.
I was pretty sure what we were looking at was a bog standard video to video workflow (with image references of Tom Cruise and Brad Pitt provided for face replacement and consistency) because we can see the camera movement and AI video generators are really bad at simulating realistic camera moves, especially handheld shaky cam. Sure, the Seedance 2.0 model is newer and thus more reliable, but it was highly unlikely that just two prompts and thirty seconds were needed to generate a full multi-angle fight scene.
I hopped over to Seedance’s website and it only took 10 seconds to find green screen footage of two stuntmen performing the same style of fight choreography we see in the Cruise vs Pitt scene. Seedance had used green screen footage for a different demo - this time using a prompt for an anime style fight scene.

I duly let LinkedIn know about my findings and posted the video below showing the green screen footage next to the AI fight scene.
Some more green screen footage showed up on a Chinese news site along with another fight video generated from the stunt performers.

Bytedance probably recorded a large library of green screen footage for training and guidance.

The same Wing Chun/Jun Fan gung-fu style choreography makes an appearance with different characters.
It’s important to note that not anyone could shoot the green screen video above. Video to video requires excellent input/source material for best results, as Seedance did. Hiring a green screen studio, stuntmen, choreographer, lighting crew and cameraman would cost a couple of grand a day on the low end. Then there is the cost of generating. We don’t yet know how often Seedance users will have unusable output. The discard rate in generative media tends to be very high. By unusable we mean 'not good enough for the big screen’ where regular errors and artefacts ruin the viewing experience.
One other thing irks me about the generated fight scene. Pitt and Cruise are pulling their punches and sometimes acting hit when there is a clear missed punch. That’s something actors and stuntmen have to do to avoid hurting each other, but in a purely AI generated video that shouldn’t be a thing. A hit should always be a very clearly visible hit.
Here’s another Seedance 2.0 fighting video that “leaked” (almost all the leaks are fighting videos as if generated fights is what the film industry and martial arts fans have always asked for). The timing, movement and distancing of the fighters is similar to the previous examples above and again the punches are being pulled:
All the demos so far have used generic prompts such as ‘two men fighting’ which means the output relies heavily on the training material. It will be interesting to see how much a user can control the fight choreography with prompts only. I suspect the fixed video length of generated footage will be an issue. If the limit is 7 seconds or 15 seconds then the model has to squeeze everything within that window, which almost always results in the model not following instructions accurately.
Notice in the UFC fight demo that well known corporate logos in the background are generated quite well, but all other text and logos are deformed because the output is dependent on the training data and references. When the model is left to fill the gaps errors occur.
So was the input really just a 2 line prompt or was it actually 2 lines, green screen video footage, and references too? The evidence appears to show that stuntmen were filmed from several angles, that a clip had to be generated for every angle, and then finally all clips were stitched together for marketing. Only Seedance knows. Some people who have had early access have been open about what they are doing…
We should also bear in mind that even if a user doesn’t upload a green screen video reference (because obviously Robinson didn't shoot any), Seedance could have been using green screen video references in the background to help guide the output. We have evidence they did shoot on green screen with the same style choreography. They could have a whole library of green screen footage on their servers to assist in generating fight scenes. (more about that in the Addendum below)
It’s still remarkable that after two years of video to video people are still unable to recognise it and we still have journalistic malpractice whenever a new AI model is released. The Corridor Crew guys have been demonstrating video to video and AI face replacement for many years now.
Here’s a generated fake trailer I made in early 2024 (almost two years ago) featuring a similar technique. If it looks impressive you’re being tricked by it. It’s just a series of stills from John Woo films, reskinned with an AI model, the AI errors cleaned up in Photoshop, then a few seconds of motion is added to each still frame, titling and credits added in After Effects, and a soundtrack generated in Udio (which has very dodgy badly pronounced Cantonese).
Did I go around saying Hong Kong cinema is toast? Of course not. Many of the same issues generative media suffers from today were slightly worse back then. The biggest change since has been the introduction of talking characters.
There will always be AI fan boys online who will read my breakdowns and say “But look where it was two years ago. Imagine where it will be in six months!”. This is a ‘Number Go Up’ fallacy that has often been used by cryptocurrency fanatics and religious extremists when they point at their growth and claim that they will own the world in the future, because they fundamentally don’t know how the world works. In the case of AI fan boys they also don’t know how the technology works and that for exponential improvement to occur they would need exponential amounts of data, compute, energy and memory alongside incredibly difficult software engineering.
But they will keep shifting the goal posts anyway. Before they used to say ‘Wait six months’. Now they say ‘What do you think it will look like in 10 years?’
Of course generative media (that’s the proper term, not ‘AI filmmaking’) and generative VFX will continue to improve, but we need to remind ourselves why audiences flock to cinemas, buy discs and merchandise, and travel across the country or the world to meet actors and filmmakers at conventions and ceremonies. Tom Cruise often risks his life to entertain us and he’s the biggest star in the world because of it. Physical talent and celebrity matters to fans and followers. That’s why the Seedance fight demo above had to use the faces of two celebrities for wide reach and hype. Without that it would have just been two stuntmen and an AI filter. Nothing to talk about.
Similarly, if physical talent and celebrity didn’t matter spectators wouldn’t spend extraordinary amounts of money and time following their favourite athletes and sports teams. They would be content replacing real sports with video games alone. But that’s not how the world works. Humans, like all animals, are social creatures who need to belong to something bigger than themselves. If we don’t look up to people who achieved greatness with physical hard work, persistence and raw talent then we will lose our sources of inspiration. Hierarchy gives humanity something to strive for. Flat societies are artificially enforced by dictators and theocrats and they become violent because they suppress the creative mind and the desire to express oneself freely.
The entertainment industry (sports, film, acting, music, literature and art) is largely controlled by agencies for that reason - for onboarding and managing the talent that audiences look up to. Film production companies and studios come and go, but the agencies run the show.
If AI guys ever manage to make a somewhat decent full movie they're going to be in for a non-surprise when they see their movie being pirated on torrents because almost nobody wants to pay money to watch an mpeg made with next to no effort or minimum effort.
The only generative media enthusiasts who will have success will be those who hire skilled production professionals, writers and actors, and even then they will need to show behind the scenes production workflows. Audiences want evidence of investment, hard work and talent.
So in conclusion, is it over for filmmakers and is “Hollywood cooked”? Even if the fight scenes coming out of Seedance were genuinely generated with prompts only the model still produces tons of errors in the form of illegible gibberish text, morphing people, low quality details in the background, and other typical AI errors throughout the video content. It seems that this model is more optimised for motion rather than fixing all the known issues that plague video generators.
That makes Seedance 2.0 useless for the motion picture industry unless you need a quick dirty plate for VFX, a quick dirty B-roll clip, or lowish quality content for social media.
I look forward to testing Seedance myself, probably via ComfyUI so I can control the output better. I’m interested in seeing how cleanly it handles video to video and if it can do variations from a single input source. I will be checking to see how well it can handle detailed fight choreography instructions instead of just ‘two men fighting on a roof’ because then I’ll be able to tell if the model is receiving guidance from a pre-recorded video source or not.
Addendum:
This blog post has been read by many thousands of people around the world. Things get lost in translation whenever too many people speak at the same time and some of them are not tech savvy. So some clarifications below.
Robinson uploaded more clips to YouTube that has more constume and character changes, but featuring the same kind of fight choreography. I won’t believe these were from prompts alone until I try it myself. There have been too many let downs in the past.
The replies to his video upload feature the standard toxic hate speech towards “Hollywood” with no regard for the thousands of workers worldwide who earn a living from every single movie produced.

Some people seem to be confused by what I said. They are assuming Robinson uploaded green screen footage. As shown elsewhere, the green screen footage is from Bytedance’s library which they could be using to guide the models output without the user’s knowledge. In fact, we know that Bytedance’s new generation of models can fetch references. Here’s an example of how the Seedream 5.0 (Seedance’s little brother) image generator can fetch external data (on the web or a server) for references, something that until now models didn’t do automatically.

There’s also another misinterpretation. Some people assume that using the green screen footage is a form of “cheating” or “AI scam”. It should not be seen that way. Human performances should be used as input for generative media. That’s a win-win situation where skilled performers and actors are employed and the AI models help craft characters and scenes, all of which should be cleaned up and edited by VFX artists and editors.
I don’t write against the use of AI. I write against the hyperbole and toxic language surrounding AI. The idea that AI can do anything and everything without human guidance and will take over all jobs is toxic, nihilist, hyperbolic and factually incorrect.
Finally, I was interviewed by Newsweek here. I was slightly misquoted in the article because they had to compress all the quotes. For example, I didn’t make the claim that Robinson said the fight video was generated in 30 seconds. That claim came from this video I linked to.
Here is the full Newsweek interview:
1) What was your first thought when you saw the video, and what drove you to debunk it so thoroughly?
The video was being widely shared on LinkedIn by people who have no experience in film production, CGI or even generative media. Sometimes these are fake accounts created by marketing firms. Whenever a new model drops they always declare that the new model spells doom for filmmakers, photographers, actors, artists, and so on.
My first thought was ‘Ah, this looks like another video to video workflow’.
Sketch to image, image to image, image to video and video to video are now the most common workflows in generative media production. Seedance’s site calls it ‘Reference to Video’ (R2V). Basically the concept is that the contours of shapes in the input video help guide the AI model to produce more predictable and reliable output. Prompts are used alongside the input media to describe what is in the scene itself.
So I went to Seedance’s website and immediately saw that they used live action green screen footage as inputs for some of their demos. They made no secret of this so they are not to blame for any deceptive marketing. In fact, I often speak with engineers at AI companies and these guys are very honest, hard working and open about the limitations of the models. It is the marketing firms and influencers who have a tendency to overhype the abilities of AI models.
I’m pretty sure that Bytedance will be optimising Seedance for action scenes because martial arts are native to Chinese culture and popular worldwide, but for best results they will need video to video workflows like they demonstrate several times on Seedance’s website.
2) Can you tell me more about your background with film and your experience with AI? How existential do you think AI really is to Hollywood?
I studied drama, literature and film production in my youth with an eye to writing and directing films but because my parents raised me in the fashion industry I ended up mostly working in photographic and video production for the fashion industry rather than film. But the production skills, equipment, applications and workflow are the same.
Over the years we have seen stories that AI would destroy photography jobs and replace photography and video in the fashion industry. I have consistently debunked these ideas in public and in-house company communications. AI models do not know what new products look like without photos being taken in the first place, and consumers demand that photos show products authentically (even when retouched). If fashion imagery isn’t accurate that can result in sales dropping badly or an increase in refunds.
My predictions turned out to be true. AI has not destroyed photography. At most we are now seeing generative images being used to compliment photography. For example, in Photoshop we use Adobe Firefly’s Generative Fill tool to remove creases or to extend backgrounds. We are also seeing image to video being used - this adds one or two seconds of motion to a photograph. None of this is perfect though. The AI output often requires manual clean up.
3) What frustrates you most about the conversation/hype around AI?
As mentioned above the marketing is toxic. It’s a form of hate speech that frequently attacks working people who have bills to pay and families to feed. Many workers, even in the digital creative field, are not technologically savvy so they become demoralised easily by toxic overhyped marketing.
4) Your post went pretty viral - did Ruairi Robinson respond to you at all? Have you heard from anyone notable about it?
Robinson’s comments were irrelevant because they were not new. He was parroting an old line and influencers quoting him were producing clickbait.
5) Anything else you'd like Newsweek readers to know?
The output of the best AI models today are far below the very high requirements of media production. They might look impressive for 7 seconds on a little phone screen, but a full length 120 minute long movie on a big TV or cinema screen is a completely different thing. You can make a two hour long AI movie today, but you’ll have to cut a lot of corners, accept a lot of errors in the images, accept the video compression is very high, and accept that only a tiny percentage of AI/tech die hards will have the patience to sit through it or even pay for it.
Despite what AI fanatics say your readers, consumers and customers matter. They’re the ones who decide what will be successful or not. If they believe articles, books, comics, films and music were made with minimal to no effort then they will give you less attention and less money for it. Consumers aren’t the zombies some people claim they are. Just because they enjoy some cheap clothing, some fast food and unlimited streaming doesn’t mean they want everything to become quickly produced and quickly consumed junk.
Audiences and martial arts fans are not asking for generated fight scenes. They’re asking for more of this…
Runway introduces Gen-4.5 Image to Video
Runway introduced Gen-4.5 Image to Video today. Here’s the intro video:
I’ll keep this blog post brief because the model suffers from the same issues I’ve explained for the last two years ever since Sora was introduced.
The intro video looks impressive, if you’re looking at it on your phone. On a laptop, computer monitor or TV not so much. The bigger the screen is the more unwatchable AI videos are. Pause the video at almost any point and the illusion of consistency and quality falls apart. Here’s a quick rundown of the sloptastic AI errors in the intro video.

Gibberish writing on store fronts and nonsense interior vehicle design.

More gibberish text. How are we supposed to enjoy a film if there are so many distractions?

The scuba diver’s face is mashed up and his hand is caught in the door instead of holding the door handle.

Lots of bad morphing and distortion.

The level of slop in this fake anime is an insult not only to anime but also to generative AI.
Because prompting alone creates a lot of slop they’ve also shown an image to video workflow starting with images generated by Google’s Nano Banana Pro model, but the lack of consistency in the character and set makes it unsuitable for professional production. You have to use photo to video, highly detailed sketch to video, or live action video to video in order to maintain some semblance and consistency from one clip to another. AI alone has too many downsides.
The Current State of Gen AI in 2026
LinkedIn AI guys keep claiming “AI is evolving fast” but most of the progress was between 2022-2024. The last year saw very little improvements to generative AI models and their own benchmarks prove that progress has slowed down a lot.
Prompting an AI model alone has failed to live up to expectations due to its lack of fine control and excessive randomness. Furthermore, copyright issues arose because a prompt could inadvertently lead a model to create someone else’s intellectual property.
Now everything in the generative AI space involves using traditionally created references for inputs:
Sketch to image generation
Sketch to 3D generation
Photo to image generation
Photo to video generation
Live performances as inputs:
Video to video generation (a form of rotoscoping and motion capture)
Voice to audio generation
MIDI to audio generation
Recorded music to audio generation
This tightens the amount of control users have over a model’s output and ensures the output is your IP and not someone else’s. Before you create any inputs you still have to aim for originality.
Regardless, these AI workflows are not suitable for most high end productions. The image and audio output by generative models don’t match conventional tools and instruments. The 3D models they output are messy or not optimal. They all require clean up by professionals.
The notion that creative artists could be replaced by machines was a flawed concept and a lie. Critics have consistently pointed out that high-quality creation requires a skilled individual with taste and specialised knowledge of their field, and that real world original references such as photography were impossible to avoid.
Generative AI doesn’t level the playing field; the skilled always produce superior media and material than the unskilled. For proof take a look at the stream of slop on LinkedIn where used car salesmen use prompts to generate unwatchable videos and claim “Hollywood is over!” while traditional artists such as the Gossip Goblin team use gen AI to make much better material than them.
Move over Sora, Google's Veo needs your hype-men now
It has been a year and a half since Sora was first previewed and when it was finally released it led to a wave of disappointment. I wrote about Sora when it was previewed and all my predictions, no surprise, turned out to be accurate. It did not take a genius to understand the amount of machine learning, engineering and compute power required to create truly cinematic quality video and realistic images is many years away and even then there is plenty of scope for errors that will always appear. That’s the nature of software.
Anyway, since Sora’s preview a dozen other competitors have tried to steal the limelight - Runway, Luma Dream Machine, Higgsfield, Kling, and also several open source models that can be used with ComfyUI.
Google was obviously not going to be left out and considering the amount of data they have access to (via search engine indexing and YouTube) it was only a matter of time until they showed off their own video generator. Now it has been released and it is called Veo 3 (previous versions went almost unnoticed).
The usual LinkedIn AI guys and hype men you have never heard of outside LinkedIn have called Veo 3 a game changer and, again, claim Hollywood’s days are over and that Veo 3 represents a democratisation of filmmaking - as if digital video cameras aren’t already ubiquitous.
The cameras in almost everyone’s pockets today are far better than the cameras used to shoot The Blair Witch Project but we don’t see thousands of new filmmakers challenging Hollywood’s dominance. Making a film isn’t just about having access to technology.
I decided to put Veo 3 through its paces by signing up for Google’s Ultra plan and cancelling by the end of the first month. It’s still pricey as hell for over $200 but if that’s the price I have to pay to educate others in the creative community who are fearing for their jobs then that’s the price I have to pay.
So the challenge is this : I’m going to test Veo 3 every day for 30 days (or when the monthly credits run out) and each day I’ll summarise the results on LinkedIn.
A friend, David Gerard, who has done extensive commentary over the years debunking cults and scams, is covering the ‘30 Days of Veo 3’ challenge on his YouTube channel. I’ll be editing this blog post each week to include his coverage below.
Everyone's a Studio Ghibli expert now
While I was offline for a while (working, coding and studying) a bunch of AI guys and anti-AI folks on social media became overnight experts in Studio Ghibli after OpenAI’s image generator let ChatGPT users generate images in the Ghibli style, or rather what westerners think is the Ghibli style.
The AI guys insisted this was a “game changer” and soon anyone would be able to generate any animation film from the comfort of their bed, while the anti-AI side overreacted by mislabelling videos of Miyazaki talking about computer animation to defend traditional animation.
I need to raise some points.
1. Unlike these overnight experts, I support the industry with hundreds of dollars worth of disc and book purchases every year. In the last year I spent about $1500 with ‘The Boy and The Heron’ blu-ray, art book and storyboards costing $300. If you support a filmmaker but you only watch their movies on a streaming service once every two years, you’re not supporting them. It seemed clear from the arguments I was reading that the AI side and anti-AI side had barely ever spent any money supporting the animation industry. They were just vying for attention on social media.

Recent purchases. Art books and storyboards should be your main source for studying animation.
2. Sites like Civit.ai have hosted downloadable LoRAs for generating Miyazaki-like images on your computer for almost two years. Where was the mass outcry then? What you saw in the last month from OpenAI and the media was marketing. You were emotionally and psychologically manipulated to think something new and threatening happened.
3. Generating images in someone's style doesn't mean anyone is going to respect you for it or let you commercialise it. At the point of sale copyright law will always apply. If you try to sell t-shirts with generated Totoro images a lawyer from Japan will reach out to you. They issue takedowns on eBay and YouTube all the time.
4. Commenters don’t know the difference between Miyazaki and Studio Ghibli. The studio doesn’t have a set style and employs various directors. Miyazaki’s style has changed over the years. He has said his influences have come from Jean Giraud to Roald Dahl and from Sanpei Shirato to Osamu Tezuka (who was influenced by Disney). One of Miyazaki’s most successful films was 'The Castle of Cagliostro', a departure from the style he is famous for.
5. A video of Miyazaki attacking AI was mislabelled. Even though he would feel the same way about gen AI, the video was actually about scripted animation algorithms used in 3D CGI (often used in gaming). The video predates the deep learning models we see today. A different kind of AI.
6. Gen AI is no threat to people like Miyazaki for a reason anyone intelligent can understand. Audiences go to the cinema or buy discs to support them because of the sheer amount of muscular and intellectual effort that is needed to make a movie like ‘The Boy and The Heron’. They won't spend money on a LinkedIn bro who generated a semi-compelling moving slideshow from his sofa. Talent matters to audiences just like it matters to sports spectators. Don't let anyone tell you it doesn't matter.
7. Don't be tricked by clips on social media. Even if Gen AI did meet the very high requirement of filmmaking and animation, it will struggle to find an audience beyond a niche. For most there’s no reason to watch automated videos. It doesn't inspire. AI videos won’t generate the kind of revenue that cinemas need to stay open. That's the key. You have to invest a lot of money to make the kind of revenue that all the connected sectors require.
So ignore the uneducated opinions that gen AI will replace all filmmaking and animation. It won’t because it can’t. Language models struggle badly enough as a coding assistant in their own domain of computer science. Ask ChatGPT to generate a Photoshop clone or refactor a 100,000 line codebase and watch it fall over itself. The language models will tell you their limits themselves.
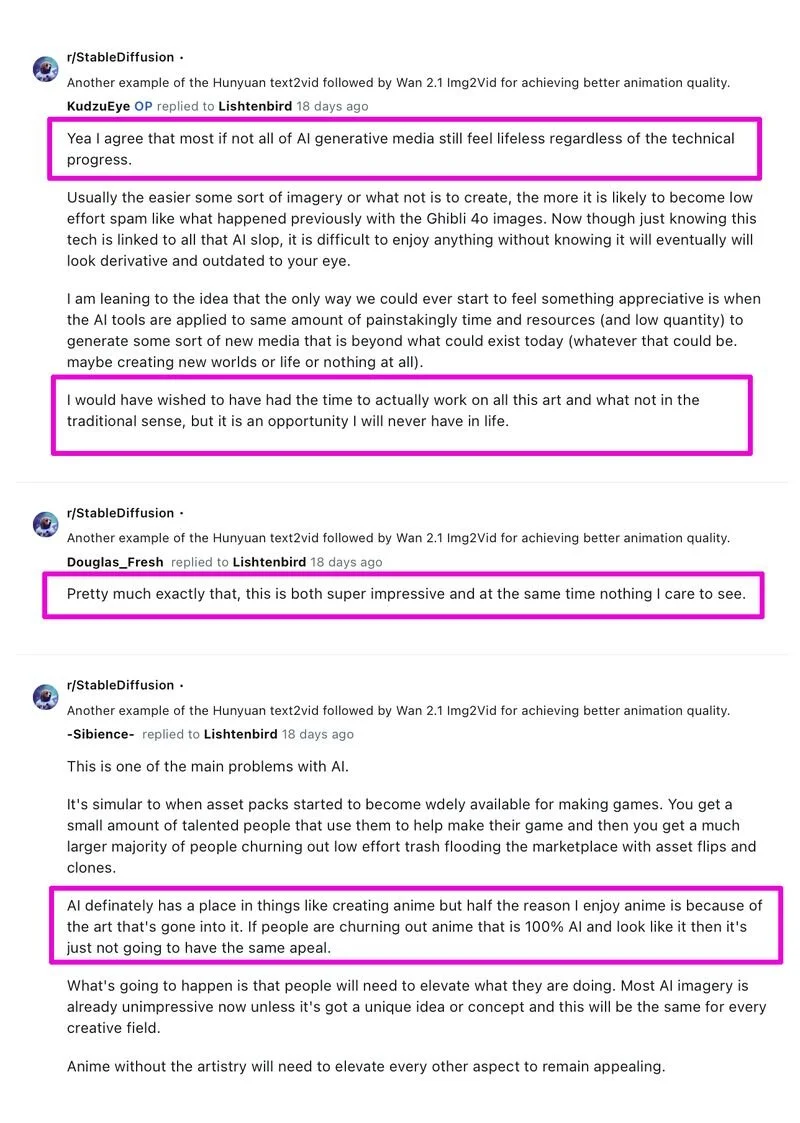
Before I end this post I want to highlight a thread I saw on the Stable Diffusion sub-Reddit. They were experimenting with the latest models to "generate animé" and even though the models appeared to output impressive images (with minimal movement), the users themselves were very critical of AI and understood that it will never compare to crafting true animation by hand. Here’s some quotes:
OpenAI releases text to video tool 'Sora' and instantly generates a wave of social media spam
A few hours ago OpenAI launched its text to video tool ‘Sora’ (Japanese for ‘sky’ but the same character 空 can also be read as ‘kara’ which means ‘empty’.) and predictably AI fanatics spammed film makers forums on Reddit and YouTube claiming the film industry’s days are numbered (they really mean Hollywood Jews, they will not apply this wild idea to film makers in the rest of the world) and that the end of the camera is coming too.
Madness.
It should be noted first of all that those wild opinions are from mostly 40-50 year old men (the typical AI YouTuber demographic) stuck in front of a computer all day who aren’t film makers and don’t have a real passion for film or story telling. They're the people generating novels with ChatGPT and flooding Amazon with these synthetic books that nobody wants to buy or making AI art that doesn’t sell. They’re the people who sent ChatGPT generated short stories and Midjourney artwork to Clarkesworld Magazine and then got banned from ever submitting again.
Let’s clarify what we are seeing here. Sora is neat, I really like what it can do. Who can’t be impressed? But it is a VFX and CGI tool. The term ‘computer generated images’ is more applicable to generative AI than 3D modelling and animation ever was. I’m sure someone out there with a big budget and time might make something neat, but it would be great if people who don’t understand filmmaking or audiences would not jump to conclusions.
With demos of Sora you are seeing a curated sample of low res videos in which the prompter has very little control over the output. Like all generative AI tools it is impossible to predict the full output which means a lot of credits and compute time is wasted generating over and over again. If the people who were bowled over by Sora looked closer they would have noticed videos replete with errors, such as an Asian woman who sometimes had two left feet, street signs with nonsense logos, billboards featuring non-existent jibbersih hanzi/kanji characters, and so on.
These issues are not easily fixed as the possible combinations of elements that can make up a scene are infinite. Bugs in the output will be a persistent problem, just like bugs in all software can never be fully quashed. Then you have the biggest compute problem - trying to animate character performances and mouth movements, which requires real time feedback, audio sync and the equivalent of doing multiple takes and shoots to get a character’s performance exactly where a story teller wants it to be. The best film directors have had their actors do numerous takes to fine tune a performance and the same applies in 3D CGI and here in GenAI.
There are also no controls for real time camera movement, changing the angle of a camera or changing the focal length or depth of field. Prompting is the most inefficient and slowest way to do these things in a virtual environment.
Films like Chariots of Fire had some cuts in the same scene shot at 24fps, 72fps and over 200fps. In animé, different animation layers/cels are animated on ones, twos and threes in the same shot. Generative video lacks these fine controls for frame rates and keyframing making the output, compute demands and costs hard to predict.
Other issues with using Sora include colour grading. Film editors and colourists understand how important log/raw footage is for the colour grading process. Art directors are always requesting sudden changes and those changes need to be done in real time. GenAI tools like Sora can only output compressed videos and you can’t change anything until you see the output. If you ask Sora to generate a video again with a different colour scheme the video itself might not be the same as the last - objects and characters could be in different positions with different errors from the last generation.
After generating a compressed video it is much harder to change the grade or colour correct. The quality will deteriorate. That’s OK for social media on a phone screen, but not for cinema. On a big screen even the smallest errors and artefacts are distracting. You don’t want audiences walking out of a screening because of quality issues, not purchasing titles because of bad reviews, or asking for refunds.
Even The Guardian’s article on Sora was hyperbolic, stating that the tool could generate video ‘instantly’ never mind the fact that that no video content can be generated instantly and that the videos themselves are extremely low resolution and feature a large number or errors that OpenAI highlighted on Sora’s page ‘Sora might struggle with simulating the physics of a complex scene or understanding cause and effect in specific scenarios. Spatial details in a prompt may also be misinterpreted, and Sora may find precise descriptions of events over time challenging’. To fix those errors will require an extraordinary amount of engineering and an unspeakably large amount of compute power to generate video, especially in native 4K or 8K with HDR support.
The film industry isn’t going anywhere and neither is filming actors on locations and practical sets. People pay to watch actors (including motion captured) and that’s not changing. When it comes to consuming entertainment, media and literature we’re talking about a shared human cultural connection. ChatGPT generated books don’t sell well because readers want to connect with real authors.
I grew up transitioning from celluloid and paint to digital photography and software. I learn every new technology that comes around, but because I have lived through all these cycles and understand consumers from a business and fan perspective I never fall for hype.
I remember clearly in the late 90s when there was fear that CGI would replace actors. It was all over the media. Paul Newman had it written into his family estate that if technology ever allowed him to be revived after he passed way that permission would never be granted. He wanted his likeness to remain his own. In 2002 Andrew Niccol of Gattaca fame made a satire called ‘Simone’ about generative AI and synthetic actors.
It never happened of course, even though CGI at its best is excellent it is never good enough. All it did was complement film. James Cameron worked as hard as possible to make Avatar as lifelike as possible but even the sequel looks like a high resolution video game composited with film footage. Hard surfaces are much easier to recreate than organic lifeforms and even water.
No new technology completely displaces and replaces what came before it. Classical instruments weren’t killed by synthesisers and Logic Pro samples. Ebooks didn’t kill books. Streaming didn’t kill vinyl records (vinyl ended up outliving the mighty iPod!). The best film directors in the world still shoot on film. Things co-exist.
We were also told that CGI would replace all traditional animation. When interviewed about his anthology ‘Memories’ which used CGI for a number of difficult shots, the great mangaka and Akira director Katsuhiro Otomo said ‘Because I draw pictures, I don’t have a plan to move away from 2D to the main use of 3DCG. 3DCG anime is like animating dolls, so people like me who have thought through the use of drawings do not have much idea about it. To begin with, it’s certainly true that Japanese like pictures with ‘contour lines’. I don’t think 2D anime will be rendered entirely obsolete, but it will stay as one of a number of diverse choices.’
Over 25 years later 2D anime is more popular than ever and Otomo’s words were prophetic. Yet despite all the evidence, you can still find tech fetishists in software engineering who insist to you that 2D animation and film photography don’t exist now. They live in a bubble so tight and small they can’t see the world outside.
At the end of the day audiences and consumers decide what becomes successful or not. You can have the most outrageous technology in the world but if your content annoys the public it won’t sell. Look at Ghost in the Shell. In 2002 they did a CGI update of the anime classic. Fans hated it and will always prefer the original. A decade later they did a live action movie remake with even better CGI. Fans hated it that too, this time for a variety of reasons.
VFX tools like these video/image generators can be incorporated into your work and if you do it smartly then it is no different from when Ryuchi Sakamoto pioneered electronic music and with the Roland MC-8 Microcomposer he introduced automated synthesiser playback.
Sakamoto never abandoned playing a classical piano in front of an audience though and as a classical composer he scored films such as ‘The Last Emperor’ and ‘Merry Christmas, Mr Lawrence’. He posthumously continues to perform on a grand piano in the mixed reality concert experience ‘Kagami’, combining the classic and the virtual even after he passed away.
Learn everything, absorb what is useful, incorporate technology into traditional arts and crafts, reject hyperbole, lovingly handcraft things that people will love, and don’t spam. The better your work is, the more of yourself that you put into your work, the more fans will reward you for it. Generative AI will have a permanent image problem associated with spam, memes making fun of AI errors, trolls hiding behind AI to mock creative workers, misinformation and climate impacts. You won’t have this image problem.
As mentioned in the first paragraph, Sora can also mean ‘empty’ so I expect that will end up describing a lot of the hype and promise of AI generated imagery replacing traditional filmmaking and photography.
Claims that AI will replace or displace most jobs are bogus
We are being told by finance bros, Twitter cretins and LinkedIn lunatics that AI (a buzzword that can mean almost anything now) will displace or replace anywhere between 40-90% of workers, enhance our productivity and make us more efficient, that it will free us up from hard work and give us more leisure time, and even more absurdly, that it will create a world of abundance for all.
Let’s break those claims down.
It is impossible for “AI” or robots to do tasks that require the level of dexterity and flexibility that only the human mind and musculoskeletal system can pull off, even ChatGPT says it would be impossible. In real life, unlike science fiction, robots need a degree of bulk to be stable and are not good at self maintenance. AI, being software, will always be buggy and the more tasks you try to teach a system the more buggy and resource hungry it becomes. If robots and AI could displace significant numbers of workers it would come with reduced reliability, reduced dexterity and increased unpredictability in many fields.
Microsoft, Meta and Google are talking up a big game about AI, but just take a look at the state of their platforms and Windows 11’s bloated and buggy condition. Google and YouTube are happy to host fake and scam ads so their moderation tools are failing to detect wrongful activity, unless they are allowing it. Instagram is infested with bots and sex pests - their AI moderation doesn’t protect users. Windows 11 still randomly crashes, looks like it was designed by a 12 year old in Microsoft Paint and users are already trying to uninstall or remove the Bing Chat bloat. That’s an operating system under development for almost five decades and it is a mess, so it’s not hard to imagine how bloated and buggy their future Godputer would be like in practice. Keep it far away from military bases and defence departments.
The people making such claims don’t have domain expertise of all the jobs and sectors they are talking about. They are salesmen, newsletter shills and report writers who attach themselves to whatever the latest trend is. Some of them were raised by house servants or at the top of a caste system, so they never learned to respect working people anyway. If their reports and posts are super optimistic and buzzwordy, and if they fail to mention the technical limitations and implementation problems of any new technologies, it’s because they don’t really know what they’re talking about. They’re no different to Deepak Chopra talking about quantum physics.
Many sectors are already operating at peak efficiency. We know that because we produce far more goods than we need and generate tons of food, electronic and clothing waste. We actually need to produce less, produce on demand, have more local production, higher quality more expensive long lasting goods, more locally repairable goods, and more just-in-time production and shipping. That’s something the polluting Sheins of the world don’t want to hear about. AI does’t solve this problem. Human willpower and cooperation solves this problem. An AI can suggest people take action against over production, slavery and pollution (things we already know) but it requires actual people to make the decisions and do it.
Whenever sectors do use automation to increase efficiency, the time saved is filled up again by producing more goods, more content, more projects and expanding product lines. Employees do not end up working less, just differently. This is exactly what we have seen in creative workflows. As a production and post-production creative, I have used and implemented everything from Photoshop Actions to machine learning based tools in our workflows to speed up work and reduce mental stress. The result of efficiency gains allowed companies to ask us to produce more content. A decade ago we used to produce about 3 images per product. Today we are likely to produce up to 6 images per product and an optional video. Implementing machine learning and automation isn’t plain sailing either and often comes with bugs that are never fully resolved.
At the pharmacy where my brother works they recently installed a state of the art robot for stock tracking and dispensing drugs. It didn’t displace any workers and requires onsite and remote support whenever there’s a hardware or software issue. That’s just how robots are.
“AI will free up our time so we can create art.” Not everyone wants to create art, but remember that one going around on the socials? It didn’t age well considering the web is now being spammed by AI art that anyone can produce and often rips off the styles of well known artists. Generative art looks attractive at first sight because our visual cortex is experiencing something ‘new’ but within moments a kind of dire existential dread sinks in, similar to when you get a robocall or a bot sends you a DM. The images are bland, lifeless and have a ghoulish vibe to them. Apparently even AI systems prefer real art and real photography to the generative kind because when they are fed only generative art their abilities begin to decay.
“Generative AI democratises artistic creation” is another one we sometimes hear, and at first glance it appears to be a true statement, but democratisation of content creation already exists with the plethora of options available. With generative AI (especially in the cloud) you are getting centralisation, it enriches chip makers, rent seekers and energy companies. It pushes up the cost of living while pushing down the cost of labour. It encourages talentless soulless executives and shareholders to tell artists their skills are near worthless. It reduces the quality of creative production and increases the ease of which spam can now be generated. It contributes not only to the enshitification of the web but the whole human experience. LinkedIn is full of 40-something men who generate images of women of colour (aka they’re saying please don’t give work to real women of colour) and claim they are part of a youth movement democratising content creation. They tried the same trick with VR, the metaverse, NFTs and crypto, by claiming they were democratising finance and being inclusive. They were largely rejected by society and then pivoted to AI, after they had caused millions of people to lose money.
We could already have a world of abundance. It is the wealthiest who rig economies and create artificial scarcity in order to drive their wealth higher. They’re doing the same thing with AI by driving up the cost of using software or playing games, increasing energy consumption and making energy scarcer, increasing pollution, and hanging the threat of AI over the heads of workers to scare them into complacency and obedience.
Driving a car is something a teenager learns to do and for the rest of our lives we mostly drive sub-consciously because we rely on known routes, laws and landmarks to assist us. It’s when laws are ignored that bad things happen. The best full self driving offered still can’t consistently perform on the level of a law abiding driver. If AI can’t actually drive cars yet (and in some parts of the world it won’t be possible at all) despite 40+ years of development, then AI won’t be able to do all those jobs that require a lot more complex real time reasoning, fluid thinking and dynamic responses than driving requires.
If the consuming public were happy with bots replacing people, then athletes and sporting events would have been replaced by bots and virtual sports already. Why spend $20 million on a footballer when a team of computer controlled footballers can play sponsored advert filled virtual matches? Golf is an extremely wasteful and inefficient use of land and resources. Why can’t that end and be replaced with virtual golf? Big Blue beat Garry Kasparov at chess in 1997. Fast forward 27 years, there's still no audience to watch AI chess players play against each other in AI chess tournaments. The technology has existed for years, but consumers (fans) won’t pay for that. They will pay to watch real athletes struggle to win. Likewise, consumers will always pay more to read books written by real people, not chatbots. They want to build an emotional connection with the author, visit the author at a meet up, and get a signed copy of the book. A book is not just words on pages.
Finally, if the cost of producing something, whether it is art, literature or clothing, is closer and closer to nothing then there’s little incentive for customers to want to pay you good money for whatever you are offering. Your offerings are a McDonald’s Happy Meal at this point, or worse. The world’s economy can’t be made up full of Happy Meal and fast fashion equivalents. Every sector depends on diversification of goods and services, from high end and artisanal to the low end mass produced.
I end this blog entry with a video of a delightful lady who runs one of Tokyo’s many popular food joints ‘Onigiri Bongo’. Japan already has a few restaurants with robot staff (they are gimmicks), but a robot cannot make a thousand onigiri a day without health and safety hazards and causing a mess, cannot build a rapport with customers and cannot make customers wait in a line outside for an hour every day. Connections, traditions and craft are important.
When I started my first novel Scrivener hadn’t been released yet.
Writing this science fiction novel took me 18 years of reading and research. Scrivener came out after I began working on it and over the years was so helpful and indispensable for managing all the notes and ideas.
Sometimes I would take an hiatus to read and research other things. Many ideas and scenes were revised or scrapped during those years but the central theme remained constant. I not only wanted the story to be ahead of its time but also contemporary enough to be relatable, so my bookmarks and notes kept growing and growing.
Finally I decided there was nothing left to study. The novel will be finished this summer. There will also be concept designs and artwork to accompany it.
Thanks to Keith of Literature & Latte for helping me stay organised for so long.

Recovered my old film school DV tape from 2001
Today I managed to finally capture my old film school DV tape. The tape had travelled with me for almost 20 years, from flat to flat and from country to country. I thought it wouldn’t have survived after so long. Tape degrades.
I was about to capture the tape in early 2020 but then covid came along and delayed those plans. I didn’t want to ask someone to capture it for me. I really wanted to enjoy the process of capturing tape just like I did when I was young. In fact, the first time I ever captured video computers weren't powerful enough to transfer live video from a camera. Computers needed a special targa capture card to import each frame individually as a targa sequence.
Finally covid subsided and after keeping an eye on eBay for a long time I found a Canon XM2 in excellent ‘almost new’ condition at a great price. The short film itself was filmed on the XM2’s big brother the XL1S, but the cameras are very similar internally. Video capture is somewhat similar to film scanning. You grab a coffee, set up the equipment, and then diligently perform the job of transferring media manually into the computer.
Connecting the XM2 for capture proved tricky. First, I had to use an old Mac with firewire. Second, Adobe Premiere stopped supporting miniDV capture a few years ago and there was no method to install a version of Premiere old enough that did still support miniDV. QuickTime still does allow firewire capture, but I discovered that the start of the tape had degraded from exposure to air and heat. Because of the damage to the tape, Quicktime was unable to capture video with audio, but it could capture the streams separately!
Capture done, you can see how little detail and resolution we worked with in those days. Imagine if we had 4K or 6K HDR cameras at the time! 🤯 The colours produced by Canon’s 3CCD system were great though. There is hardly any grading applied to the images below, in some scenes none at all.

Screenshots from ‘花’ (‘Hana’) a short film in Japanese that I wrote, shot and directed in film school back in 2001 starring my friend Ryoko who was a news reporter on Nihon TV at the time.
I made a vertical trailer for social media which can be watched below.
Getting it right requires time...and feedback
My favourite camera will probably always be my Leica M3, a custom version with a genuine Italian rosewood body. Whenever I take it to camera shops for servicing it always receives the same compliment 'It's a unique piece!'

Leica M3 (photo taken with an iPhone :p)
I've used just about every type of camera over the years, but what attracted me to the M3 was that Leica put over a decade of research into it because they wanted to make sure they got the M series just right with the very first release (an extremely rare feat for any device).
Over that decade, Leica frequently interacted with customers to help them design the M3. Users wanted it to be streamlined and ergonomic compared to the irksome and intimidating Leica III. Because the principal market was street photography, the M3 also had to feel second nature to users so that they could quickly capture moments around them. It also had to be easy to repair and recycle.
It was one of the earliest examples of a company asking for global customer feedback and beta testing the hell out of the product. The incredible results of that collaboration haven't been replicated so well since. Evidence of that can be seen in the fact that people still enjoy using the M3 65 years later.
Only one change was made during the M3's life-cycle - a change from a double stroke to single stroke advance lever (both equally useful). As time went by, Leica added a few more bells and whistles to the M series that weren't possible in the early 1950s, and sometimes they made mistakes in doing so, but the tradition of keeping their renowned product line pure still exists today in the M10.